最新情報 2021.03.31
マイクロコントローラで動作可能な自動音声コマンド認識のための軽量CNNモデルを発表

概要
非タッチベースのアプリケーションへの関心が高まっており、IoTデバイスでの自動音声コマンド認識(ASCR / ASR)の必要性が高まっています。 この記事では、マイクロコントローラー上のASR用の新しい軽量畳み込みニューラルネットワーク(CNN)を紹介します。 提案のモデルは、63k未満の非常に少ないパラメータ数を持つ現在の最先端のネットワークに匹敵します。 新しいモデルは、Google音声コマンドV2データセットで96.13%の精度を提供します。 同じデータセットの以前のモデルの結果の比較研究も提示されます。
1. Introduction
現在、ASRはニューラルネットワークが非常に計算コストが高いため、操作にクライアントサーバーモードを必要とするGoogleスピーチ、Siri、Alexaなどのヒューマンコンピューターインターフェイスを使用して実行されています。 したがって、インターネットにアクセスできないデバイスの場合、デバイス自体が非常に計算コストの高いネットワークを実行できないため、音声認識を実行することは実行不可能なオプションになります。 この論文では、マイクロコントローラのような低電力デバイスに適した非常に軽量なニューラルネットワークを紹介します。
ネットワークは、マイクロコントローラーで実行するために次の制約を満たす必要があります:
- メモリフットプリント:数十キロバイトの範囲の非常に小さなメモリフットプリント
- 低計算能力:数十MHzからサブ200MHzの範囲の限定されたMCPSプロセッサコア
- オフライン:すべての処理は、クラウド接続なしでローカルで実行する必要があります
この論文は次のセクションで構成されています。 2:モデルアーキテクチャ、3:トレーニング方法論、4:結果。
2. モデルアーキテクチャ
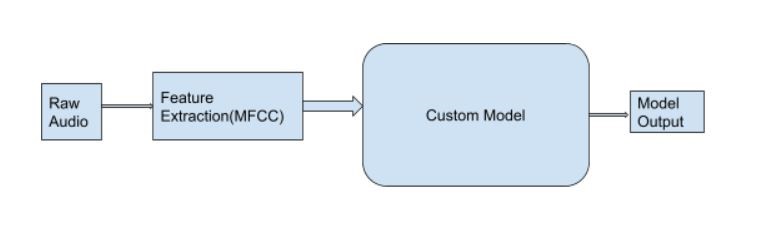
モデルは、Tensorflowバックエンドを備えたKerasを使用して構成されています。 オーディオファイルは1つの単語で構成されています。 したがって、現在のモデルは分類モデルと考えることができます。 各オーディオファイルは、16000 Hzにサンプリングされ、ネットワークへの入力として提供される単一チャネルのモノラルwavファイルです。 40バンドのメル周波数ケプストラム係数(MFCC)の特徴がオーディオサンプルから抽出され、ネットワークに供給されます。 これらのMFCC機能は、分類結果を生成するためにカスタム convolutional neural network (CNN) に供給されます。
3. 実験結果
3.1 モデル統合
すべての実験で、githubリポジトリ[3]が参照されました。 すべての実験の均一性を維持するために、カスタムモデルを除くリポジトリのすべての側面が同じに保たれました。
3.2 実験のセットアップ
実験で使用したデータセットは、次のキーワードが設定されたGoogle音声コマンド(GSC)12クラスです: ‘_ unknown ‘、 ‘left’、 ‘on’、 ‘stop’、 ‘right’、 ‘off’、 ‘down’ 、 ‘up’、 ‘no’、 ‘go’、 ‘yes’、 ‘ silence _’ [1]。 すべてのキーワードは16kHzでサンプリングされ、持続時間は1sです。
GSC V2は36個のフォルダーで構成され、データセットは事前定義されたパーセンテージに基づいてトレーニング、検証、およびテストに分割されます。 全データセットの10%がテストとして分割され、10%が検証として分割され、残りの80%がトレーニングデータとして分類されます。 上記のキーワードリストに含まれないキーワードは不明に分類されます。 トレーニングとテストセットの構成は、次の表のとおりです。
| Class | Counts | Class | Counts | |
| on | 3086 | on | 396 | |
| right | 3019 | right | 396 | |
| stop | 3111 | stop | 411 | |
| up | 2948 | up | 425 | |
| down | 3134 | down | 406 | |
| no | 3130 | no | 405 | |
| go | 3106 | go | 402 | |
| left | 3037 | left | 412 | |
| yes | 3228 | yes | 419 | |
| off | 2970 | off | 402 | |
| unknown | 6154 | unknown | 816 | |
| silence | 3077 | silence | 408 |
Google音声コマンドデータセットに存在するバックグラウンドノイズクラスは、クラスとしてのトレーニングとは見なされませんが、他の音声信号と混合されて、拡張データが作成されます。 無音クラスは、ランダムファイルにゼロを掛けることによって生成され、無音クラスの数は、任意のランダムフォルダー内の全ファイルの10%として計算されます。 すべての測定基準と方法は、標準的な慣行[1,2]に準拠しています。以下の表は、[1]を参照して生成されています。
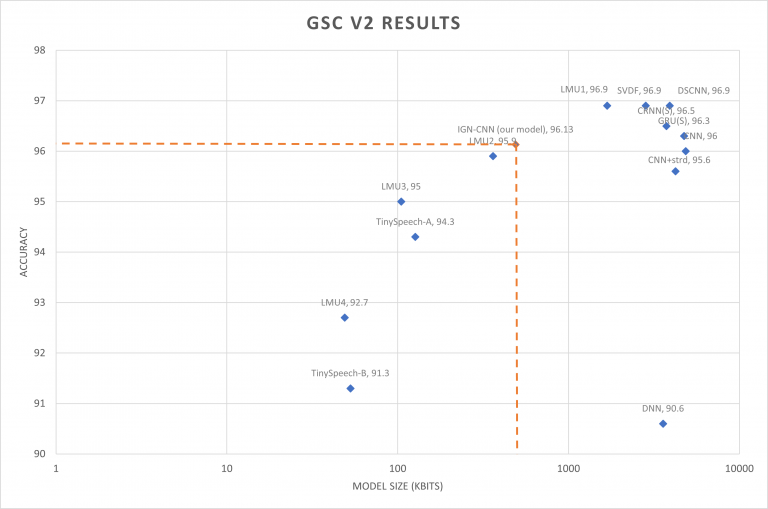
| Model | Accuracy | Model Size (Kbits) |
| DNN | 90.6 | 3576 |
| CNN+strd | 95.6 | 4232 |
| CNN | 96.0 | 4848 |
| GRU(S) | 96.3 | 4744 |
| CRNN(S) | 96.5 | 3736 |
| SVDF | 96.9 | 2832 |
| DSCNN | 96.9 | 3920 |
| TinySpeech-A | 94.3 | 127 |
| TinySpeech-B | 91.3 | 53 |
| LMU1 | 96.9 | 1683 |
| LMU2 | 95.9 | 361 |
| LMU3 | 95.0 | 105 |
| LMU4 | 92.7 | 49 |
| IGN-CNN(our model) | 96.13 | 490 |
4. 結論
組み込みマイクロコントローラーデバイス用に最適化された、ASR用の新しい軽量CNNベースのモデルが開発されました。 Google SpeechCommands V2データセットを使用して、同等のモデルに対してモデルのベンチマークを行いました。 精度の結果とモデルの総フットプリントは、一般的な最先端のモデルに匹敵します。 このモデルアーキテクチャは、主要な半導体メーカーの低コストマイクロコントローラーの複数のバリエーションに導入されています。
5. 参考文献
- Peter Blouw, Gurshaant Malik, Benjamin Morcos, Aaron R. Voelker, and Chris Eliasmith “Hardware Aware Training for Efficient Keyword Spotting on General Purpose and Specialized Hardware”, https://arxiv.org/pdf/2009.04465.pdf
- Oleg Rybakov, Natasha Kononenko, Niranjan Subrahmanya, Mirko Visontai, Stella Laurenzo, “Streaming keyword spotting on mobile devices”, https://arxiv.org/pdf/2005.06720.pdf
- Reference code, https://github.com/google-research/google-research/tree/master/kws_streaming
オススメの記事