最新情報 2021.01.20
ディープラーニングを使用したコンテナコードの自動認識

ディープラーニングは、コンピュータービジョンの急速な発展をもたらしました。コンピュータービジョン技術の多くの新しいアプリケーションがディープラーニングで実装され、現在、我々の日常生活の一部となっています。
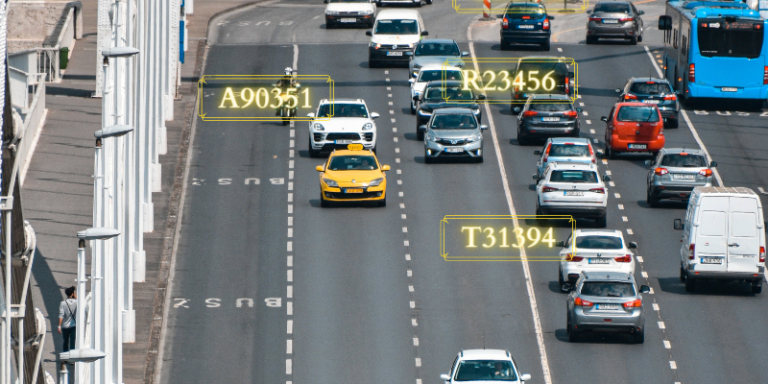
特に海運業界は、このテクノロジーの大きなメリットを認識し始めています。海運会社、また商社は毎日、何万のコンテーナーを処理しているため、リアルタイムで『自動コンテナID』及び『ISO番号検出』することが必要です。
コンテナ識別システムでは、一連の文字と数字で構成されるISOフォーマットが使用されています。ターミナルゲートやその他のチェックポイントは多数のコンテナを処理するため、コンテナが識別されるシーケンスは常に適切に実行されていない可能性があります。コンテナID及びISO番号の人的検査と手動記録では、作業ミスが発生する可能性があるでしょう。これらは税関職員とターミナルオペレーターの通関確認プロセスの作業効率を妨げます。
イグニタリアムのエンジニアは、現在の手動コンテナ認識システムでの上記の運用上の課題を理解し、コンテナのIDとISO番号を自動検出し、代替のディープ・ラーニングに基づくコンピュータービジョンのソリューションを概念化して開発しました。
このプロジェクトの主要なモジュールに移る前に、現在使用されているコンテーナー識別システムの概要を見てみましょう。

コンテナ IDは、オーナコード、製品グループコード、ライセンス番号およびチェックディジットで構成されるISOに基づいた11桁の番号です。下の4桁の番号はコンテーナーのカテゴリーとサイズを表します。これらの各コードは、コンテナの輸送において非常に重要な役割を果たし、コンテーナーの管理と安全性に関するサプライチェーン内のすべての組織に貴重な情報を提供します。
データの準備:
データの収集は、パラメータの情報収集および測定プロセスです。モデルをトレーニングするには、十分な関連するデータ量が必要です。また、ラベリングもトレーニングの重要な部分です。トレーニング結果は、データラベルが正しい場合にのみ最大の精度をもたらします。その為に私たちは、いくつかのコンテナ動画を収集し、これらの動画から画像を引き出しデータセットを生成しました。コンテナ、テキスト領域、文字のラベリングは、ラベリングアプリを使用しました。ラベリングアプリの例はここにあります。 LabelImg 又は LabelMe
このプロジェクトの主要なモジュールは下記の通りとなります。
- コンテナの検出
- テキストの検出
- 文字の検出
- 文字の分類
1. コンテナの検出:
オブジェクト検出は、画像または動画内のオブジェクトを検出するのに役立つコンピュータービジョン技術です。動画(ビデオ)分析と画像理解との密接な関係により、近年多くの研究の注目を集めています。ディープラーニングに基づく多数のオブジェクト検出フレームワークが、オブジェクトの検出作業に使用できます。 ディープ・ラーニングを使用したオブジェクト検出アルゴリズムの概要については、こちらを参照下さい。– An overview of deep learning based object detection algorithms.


コンテーナーの検出には、RetinaNet ネットワークのカスタマイズされたバリアントが利用されます。RetinaNetは、バックボーンネットワークと2つのサブネットワークで構成される複合ネットワークです。 バックボーンネットワークは、画像の畳み込み特徴マップを生成する役割を果たします。一つのサブネットワークは、バックボーンネットワークからの出力に基づいて分類結果を生成し、もう一つのサブネットワークは、バックボーンネットワークからの出力を使用して回帰タスクを実行します。使用されるプリ・トレーニングされた weight は、ResNet50からのものです。RetinaNetアーキテクチャの詳細は、こちらを参照して下さい。 related post

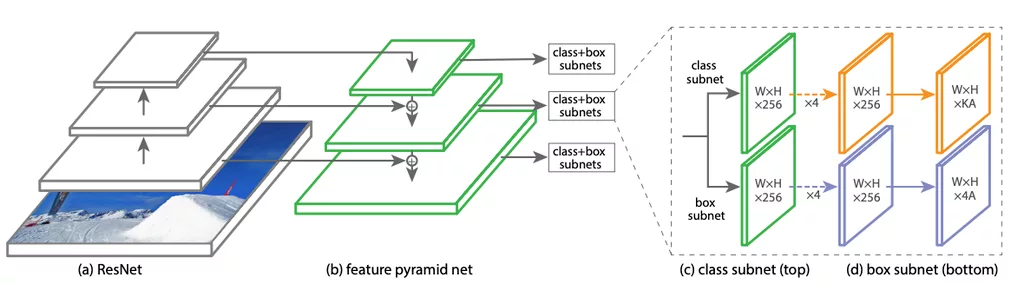
RetinaNet モデルのトレーニングと評価には、2つの csv ファイルが必要です。コンテナのラベリング中に生成されたXMLファイルがパース(解析)され、annotation.csvファイルが生成されます。annotation.csv ファイルには、入力画像の箇所、そのバウンディングボックス値および該当するラベルが含まれます。 <path/to/image>, <xmin>, <ymin>, <xmax>, <ymax>, <label> 。 classes.csv ファイルには、データセット内の一意のすべてのクラスラベルと、それに該当するインデックス値が含まれます。モデルへの入力はこれらの CSV ファイルとなり、トレーニングが完了すると、トレーニングされたウェイトファイルが保存されます。予測を行うために、このトレーニングされたモデルを推論モデルに変換します。テスト中、コンテナのバウンディングボックス値とそれに該当するスコアおよびラベルが返されます。閾値を設定することで、ボックスをフィルターできます。出力を視覚化するために、OpenCV コンポーネントを利用できます。
ベースのRetinaNetリポジトリは、こちらで入手できます。 keras-retinanet.
2. テキストの検出:
コンテナが検出された後、IDとISOに該当するテキスト領域を検出する必要があります。画像内のオブジェクトのサイズ、箇所、照明およびテクスチャの違いにより、画像でのテキストの検出は、コンピュータービジョンで最も難しいタスクの1つになっています。 いくつかのオブジェクト検出アルゴリズムのうち、セマンティック・セグメンテーション・アルゴリズムはテキストの検出に適しています。
セマンティック・セグメンテーション:
セマンティック・セグメンテーションは、画像内の全画素にラベルやカテゴリを関連付けるタスクです。セマンティック・セグメンテーションには、道路標識の検出、自動運転車の運転可能領域の検出など、多くのアプリケーションがあります。Keras セマンティック・セグメンテーションの概要については、Semantic Segmentation 及び A Beginner’s guide to Deep Learning based Semantic Segmentation using Keras を参照下さい。


セマンティック・セグメンテーション・ネットワークは、エンコーダー・デコーダー・アーキテクチャに従います。いくつかのプリ・トレーニングされたモデルも利用可能です。したがって、最初のステップは、セマンティック・セグメンテーションタスクに適切なベース・ネットワーク及びセグメンテーション・ネットワークを選択することです。セマンティック・セグメンテーションに必要となるアーキテクチャを選択することに加えて、入力のディメンションを選択することも重要です。入力サイズが大きい場合、より多くのメモリーが消費され、トレーニングが遅くなります。
マスク画像は、アノテーションされた json から生成されました。 エンコーダーから生成されたフィーチャー・ベクトルはデコーダー・モデルに渡され、生成されたリザルト・ベクトルは「numpy」機能を使用して元の画像形状にマッピングされます。結果を元の画像にマッピングするために、いくつかの画像処理技術を行いました。ベースリポジトリは、次より入手できます。image-segmentation-keras.
3. 文字の検出:
文字の検出には、カスタムRetinaNetネットワークを利用しました。システムへの入力は、annotation.csv ファイルと classes.csv ファイルです。annotation.csv ファイルには、各文字のバウンディングボックス・アノテーションとそれに該当する画像のパスが含まれています。テスト中、入力は検出されたテキストのクロップで、出力はOpenCV機能を使用して視覚化できます。

4. 文字の分類:
文字の分類は、カスタムCNNモデルを使用しました。畳み込みニューラル・ネットワークにはいくつかの層があります。畳み込みニューラル・ネットワークの概要については、 (Convolutional Neural Networks) と (Understanding of Convolutional Neural Networks) を参照下さい。 モデルのコンパイルは、Adam や RMSprop などのいくつかのオプティマイザーを使用できます。validation loss, train loss, Val 精度など、トレーニング中のモデル評価にさまざまなメトリックを使用できます。オプティマイザーの損失値は、問題のステートメントに応じて選択できます。
CNNモデルへの入力は、カスタムRetinaNetからのキャラクター・クロップです。数字のクロップ またはアルファベットのクロップのいずれかで、個別にトレーニングができます。

精度:
システムの成功は、各モジュールを正しく検出して分類する機能として定義できます。結果を分析すると、カスタムRetinaNetネットワークが1.4の最小損失でより良い結果をもたらすことが分かりました。テキストの検出の場合、セマンティック・セグメンテーションは1%のエラーでIDとISO番号を検出します。文字の検出は同じRetinaNetモデルを使用して行われ、エラーは0.5でした。カスタムCNNモデルは、AlexNetなどの他の分類ネットワークと比較して軽量であり、文字の分類の精度は99%です。
結論:
イグニタリアムのシステムは、コンテーナのIDとISO番号を自動検出し、認識するように設計されており、コンテナがターミナル・ゲートに入る時に手動で記録する作業を減らすのに役立ちます。このシステムは、ターミナルゲート、ヤード及びクレーンなどの荷積み、荷降ろしの場面で、効果的なコンテーナ管理と操作を容易にします。将来的なパフォーマンスを改善として、複数のRetinaNetモデルを一つの CRNN モジュールに置き換えることを検討できます。
オススメの記事