最新情報 2021.06.09
FPGAでのディープニューラルネットワークモデルのハードウェアアクセラレーション( Part 1 of 2)

人工知能は、以前は不可能と思われていた分野でのアプリケーションを発見することにより、広く普及しました。機械学習のサブフィールドであるディープラーニングは、その高い精度と効率により、すべてのAI問題に対する最先端のソリューションになりました。 先進運転支援システム(ADAS)、ロボット、自動運転車両、産業オートメーション、航空宇宙、防衛などのアプリケーションでリアルタイムの意思決定を行うのに役立ちます。正確な意思決定とリアルタイムの動作を実現するには、大量のデータを処理する必要があります。 ディープニューラルネットワーク(DNN)モデルは、多数のニューラルネットワークレイヤーを使用してこれを実現します。
ディープニューラルネットワーク
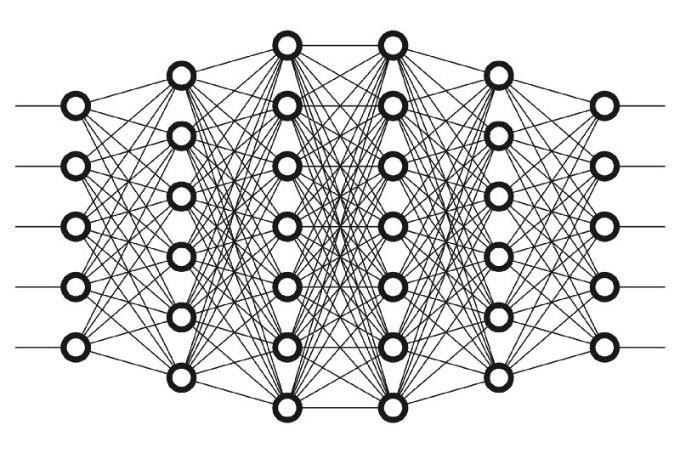
ディープニューラルネットワークは、コンピュータービジョン、音声認識、自然言語処理などのさまざまなアプリケーション向けの最先端のソリューションです。 人工ニューラルネットワークは、ニューロンと呼ばれる多数の単純な要素を結び付ける数学的構造であり、それぞれが単純な数学的決定を行うことができます。浅いニューラルネットワークには、入力層、1つの隠れ層、出力層の3つの層しかありません。 隠れ層の数が増えると、ニューラルネットワークはディープニューラルネットワーク(DNN)になります。したがって、ディープラーニングは、多くの処理層で構成される人工ニューラルネットワークのクラスと見なすことができます。それらはより正確であり、より多くのニューロン層が追加されるにつれて精度が向上し続けます。重要なディープニューラルネットワークモデルには、フィードフォワードニューラルネットワーク、再帰型ニューラルネットワーク(RNN)、畳み込みニューラルネットワーク(CNN)があります。
ディープニューラルネットワーク用ハードウェアアクセラレータ
ハードウェアアクセラレーションは、CPUのみでのソフトウェア実行と比較して、アプリケーションが高計算タスクを専用ハードウェアにオフロードして高効率を達成するプロセスとして定義されます。 リアルタイムで正確な結果を得るには、より大きなデータセットで動作するより優れたモデルが必要です。 また、意思決定にかかる時間も重要な要素です。 新しいディープラーニングモデルが進化するにつれて、モデル構造はより複雑になります。したがって、膨大な数の操作とパラメーター、およびより多くの計算リソースが必要になります。ハードウェアアクセラレータの3つのオプションは、GPU、ASIC、FPGAです。

GPUは、大規模な並列処理によって画像を処理するように設計されていますが、現在、ビッグデータ分析、高スループットとメモリ帯域幅を必要とするアプリケーションの一部の高速化で使用されています。GPUは並列処理に優れています。それらは、同じ操作が何度も連続して必要とされる場合に高速化することができます。 しかし、GPUは大量の電力を消費するため、エッジデバイス、特にバッテリー駆動のデバイスで有効にする必要があるDNNアプリケーションに課題が生じます。GPUは、大きなサイズの入力バッチを処理する機能でスループットを実現しますが、通常、レイテンシは高くなります。そのため、レイテンシが重要なアプリケーションには適していません。

ASICは、特定の目的またはアプリケーション用に特別に設計された集積回路です。これらは、特定の1つのアプリケーション向けに電力とパフォーマンスの点で高度に最適化されています。I / O帯域幅が少なく、メモリやその他の計算リソースが限られています。低電力で適度なパフォーマンスを実現できますが、デメリットは、それらを実現するための開発時間とコストが高いことです。

FPGAは、プログラマブルロジックに高度な計算タスクを割り当てることにより、アルゴリズムの一部を高速化するために使用できます。これらは、広範囲な並列処理によって高いパフォーマンスを実現すると同時に、GPUと比較してエネルギー効率が高く、ASICと比較して市場投入までの時間とコストが少なくて済みます。FPGAのもう1つの重要な特徴は、次のとおりです。GPUとASICでは不可能な再構成可能性。 ディープラーニング構造は日々進歩しているため、再構成可能性は利点です。
次のセクションでは、FPGAをハードウェアアクセラレータと見なす理由を示します。
ハードウェアアクセラレータとしてのFPGA:
GPUと比較した場合、ASICとFPGAは I/O 帯域幅が少なく、メモリやその他のコンピューティングリソースが限られていますが、低電力で中程度のパフォーマンスを実現できます。 ASICは電力とパフォーマンスが最適化されていますが、コストと開発時間はそれ以上です。 また、柔軟性がありません。 GPUおよびASICの代替として、FPGAベースのアクセラレータが現在使用されています。これは次の利点があるためです。
- FPGAは、GPUと比較して電力あたりのパフォーマンスが高いため、DNN計算と推論の有力な候補となります。
- アーキテクチャはカスタマイズ可能で柔軟性があるため、必要なリソースを使用できます。
- 低レイテンシで大規模な並列処理を備えた高スループットを提供します。
- FPGAにはブロックRAMがあり、オフチップメモリと比較してより高速なデータ転送が可能です。
- FPGAは、アプリケーションに応じて再構成可能です。 これにより市場投入までの時間を短縮できます。 新しい機械学習アルゴリズムが進化するにつれて、ASICと比較した場合、開発時間と再構成可能性が少なくなり、より優れたオプションになります。
- 電力効率とスループットは別として、FPGAにデプロイされたDNNの速度は、推定アルゴリズムが計算で低い数値精度を使用する場合にさらに向上する可能性があります。 たとえば、量子化プロセスは32ビットまたは64ビットの浮動小数点ネットワークモデルを固定小数点に変換します。これにより妥当な精度を維持することで計算が削減されます。
一方、エンジニアがFPGAを採用しない主な理由の1つは、プログラミングの難しさです。 FPGAは、VHDLやVerilogなどのハードウェア記述言語(HDL)コーディングを使用して機能を記述することによってプログラムされます。 これは、CやC ++などの通常のプログラミングとは異なります。
複雑さを軽減するために、高位言語をHDLコードに合成する高位合成(HLS)のようなツールが存在します。 FPGAに推論を実装するために、FPGAベンダーやその他のサードパーティ企業によって開発されたさまざまなハードウェアフレームワークがあります。 ザイリンクスとインテルには、他のフレームワークよりもパフォーマンスを向上させる独自のフレームワークがあります。 ハードウェアフレームワークには、OpenCL、IntelのOpenVino、ザイリンクスDNNDK、ザイリンクスVitis AIがあり、ブログのパート2で取り上げます。
オススメの記事